
Lost in Translation: Where LLMs Struggle Beyond English
GenAI is only as global as the languages it truly understands.
While the promise of today’s large language models is that they will provide universal understanding; in reality, most are fundamentally biased by their training datasets toward English and Western culture. The result? A widening gap between GenAI’s capabilities and its real-world utility in non-English contexts, especially for organizations operating across Asia, Latin America, Africa, and the Middle East.
It’s a cultural and economic fault line in addition to being a technical limitation. When GenAI systems misunderstand the way people speak, they also risk misinterpreting how they think, what they value, and how decisions are made. It affects business culture, how children learn and express ideas, and how entire economies evolve. A language not included in a model means a culture that potentially gets left behind in seeing the full benefits AI can bring.
At Articul8, we’re addressing this head-on by developing culturally informed language evaluation frameworks that assess language fluency and appropriateness to guide better model selection.
The Token Gap: Why Multilingual Models Underperform
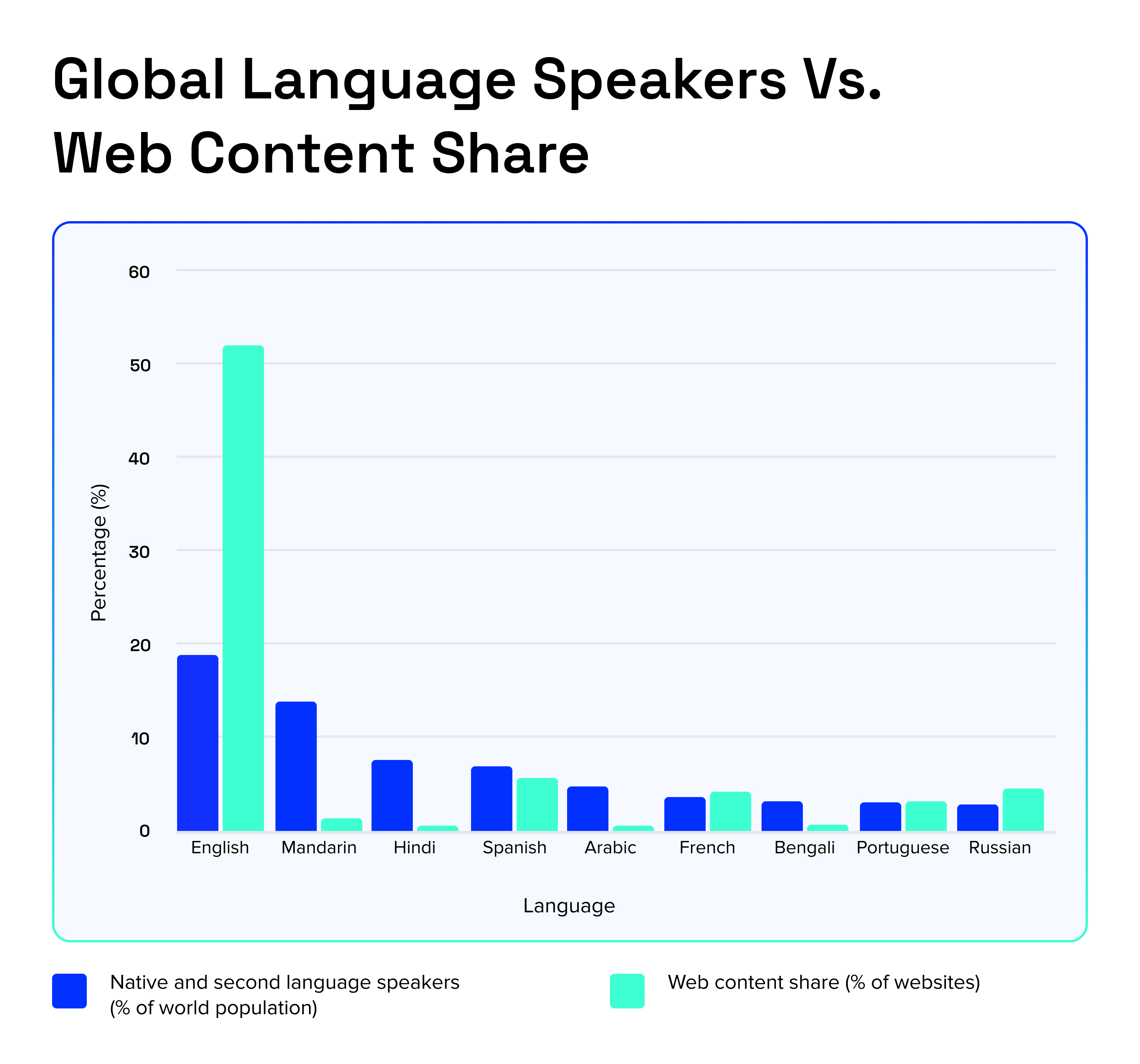
Let’s start with the data. Most Large Language Models (LLMs) today are predominantly trained on publicly available internet data, which is heavily skewed towards English. According to a report from W3Techs, English accounts for 49.3% of all websites with an identifiable content language.
This creates deep underrepresentation, not only in raw data volume, but also in linguistic diversity, register coverage, and real-world usage patterns. While data availability matters, many observed failures stem from how models internalize and evaluate language, not just how much text they are trained on.
So How Do We Know What “Good” Looks Like?
Here’s the second problem: the most popular benchmarks being used to evaluate LLM outputs are almost entirely in English. Benchmarks like MMMU-Pro and ARC-AGI-2 test logic and reasoning – but not linguistic precision in non-English contexts.
Even multilingual benchmarks like MMLU-ProX and localized language benchmarks emphasize common sense reasoning and question answering in academic subjects, but they often fall short of replicating real-world scenarios. Real-world applications require specificity, particularly in critical sectors such as automotive, financial services, legal, and healthcare, where clarity, tone, and cultural alignment are crucial. A mismatch in appropriateness, tone, or cultural fit can lead to the perception that a model is unsuitable for a specific cultural context.
To address this gap, we've developed a novel evaluation framework, LLM-IQ, that holistically evaluates the response quality in specific languages, measuring not just what is said, but how it's expressed: considering clarity, cultural relevance, and contextual appropriateness that truly resonate with target audiences.
Why Japanese Is a Strategic Test Case
We started with Japanese because it exemplifies the depth of this challenge.
Japanese denotes linguistic complexity through its intricate honorific system, multiple writing scripts, indirectness and context-dependent grammar. Fluency in Japanese demands more than translation accuracy; models must infer meaning, understand relationships, and express ideas with cultural precision.
The language's deeply embedded social hierarchy and context within its structure require a balance of tone and appropriateness. For example, responses that are too informal will be considered impolite in business settings. Conversely, being overly polite can be perceived as inappropriate.
In contrast, existing Japanese LLM benchmarks such as MT-Bench and Jaster focus on general language proficiency: common sense reasoning, Q&A, translation, and semantic analysis. They don't capture the nuances of how language is actually used in business contexts. AI platforms built on these benchmarks often fail to deliver native-like responses that satisfy real enterprise users. This makes Japanese an excellent test case for assessing language intelligence with Articul8’s LLM-IQ framework.

What We Built: A Culturally Informed Linguistic Evaluation System
To address the limitations with evaluation of language fluency and proficiency, Articul8 developed a multi-tiered framework that augments GenAI technology with human expertise and goes beyond conventional methods. The approach we created to evaluate LLMs involves:
- Model Selection: Our analysis examined 10 LLMs including general-purpose models such as GPT5, Claude Sonnet 4.5, Gemini 3, and Llama 4 Scout, trained on multilingual datasets and designed for broad applicability across languages. We also evaluated openly available Japanese-optimized models such as Llama-3-ELYZA-JP and ao-karasu-72B, which feature additional training on Japanese-specific data.
- Test Scenarios: We designed a benchmark consisting of hundreds of questions to assess complex scenarios requiring linguistic nuances such as politeness level and idiomatic expressions, familiarity with regional dialects from various parts of Japan, translation accuracy, comprehension of vertical text, numerical counters and topic drift.
Automated Qualitative Assessment: We employed LLM-IQ agent, our proprietary evaluation agent designed for enterprises to benchmark and compare large language models (LLMs) without the overhead of prompt engineering, dataset curation, or framework configuration. For more information about LLM-IQ, refer to this blog.
The LLM-IQ agent assessed each model’s responses for language quality based on the following criteria:
- Fluency and Naturalness: Does the response demonstrate native-like natural expression and grammatical accuracy without awkward or machine-translated phrasing?
- Coherence: Does the response present a logical structure with smooth transitions between sentences and avoid unnecessary repetition?
- Cultural Appropriateness: Does the response align with Japanese cultural norms through appropriate language, politeness levels, and stylistic choices for the given context?
- Consistency: Does the response maintain uniform tone, style, and formality throughout?
- Clarity: Does the response convey its meaning clearly and precisely without ambiguity or vague language?
These five dimensions gave us a comprehensive view of model performance, moving beyond simple accuracy metrics to capture the nuanced quality that end users experience.
How We Scored Quality
Each LLM response was evaluated across the above criteria on a 3-point scale (0-2) developed by expert linguists to reflect how users experience language quality in real-world settings.
Across all evaluated categories, LLM-IQ scores demonstrated strong alignment with independent human expert assessments, validating the framework’s ability to reflect real-world language quality as experienced by native speakers.


Results
Articul8’s LLM-IQ evaluation results show that Gemini-3-Pro demonstrates exceptional performance, achieving top scores in coherence, consistency, and fluency. Claude Sonnet 4.5 follows as a strong performer, particularly in coherence and appropriateness.
Notably, model size does not guarantee better performance: the 8B-parameter Llama-3-ELYZA-JP-8B outperforms several 70B+ models, demonstrating that targeted Japanese fine-tuning can be more impactful than scale alone. However, not all Japanese fine-tuned models are equal: while ELYZA-JP-8B shows excellent results, ao-karasu-72B Japanese underperforms in our tests.
However, across all models, LLM-IQ exposes significant gap in qualitative language proficiency and cultural appropriateness for LLMs outputs in Japanese. While the models exhibit strong performance in language fluency and clarity, they frequently struggle to maintain consistency, coherence, and cultural appropriateness. LLM-IQ flagged several language use anomalies described below. Expert Japanese linguists then validated these automated findings, establishing correlation between LLM-IQ's scoring and expert judgement.
The most common issue LLM-IQ flagged was inappropriate formality levels. Japanese language uses a precise formality system for written communication-
- De-aru-tai- The neutrally formal style used in newspapers and reports to maintain objectivity
- Desu-masu-tai- The respectful style for professional interactions that signals proper business etiquette.
When Gen AI systems respond with inappropriate formality levels and colloquial expressions typically used in verbal conversations, they undermine user confidence in the credibility of the response. In the example below, the question is framed in neutral polite tone, but the response is informal.
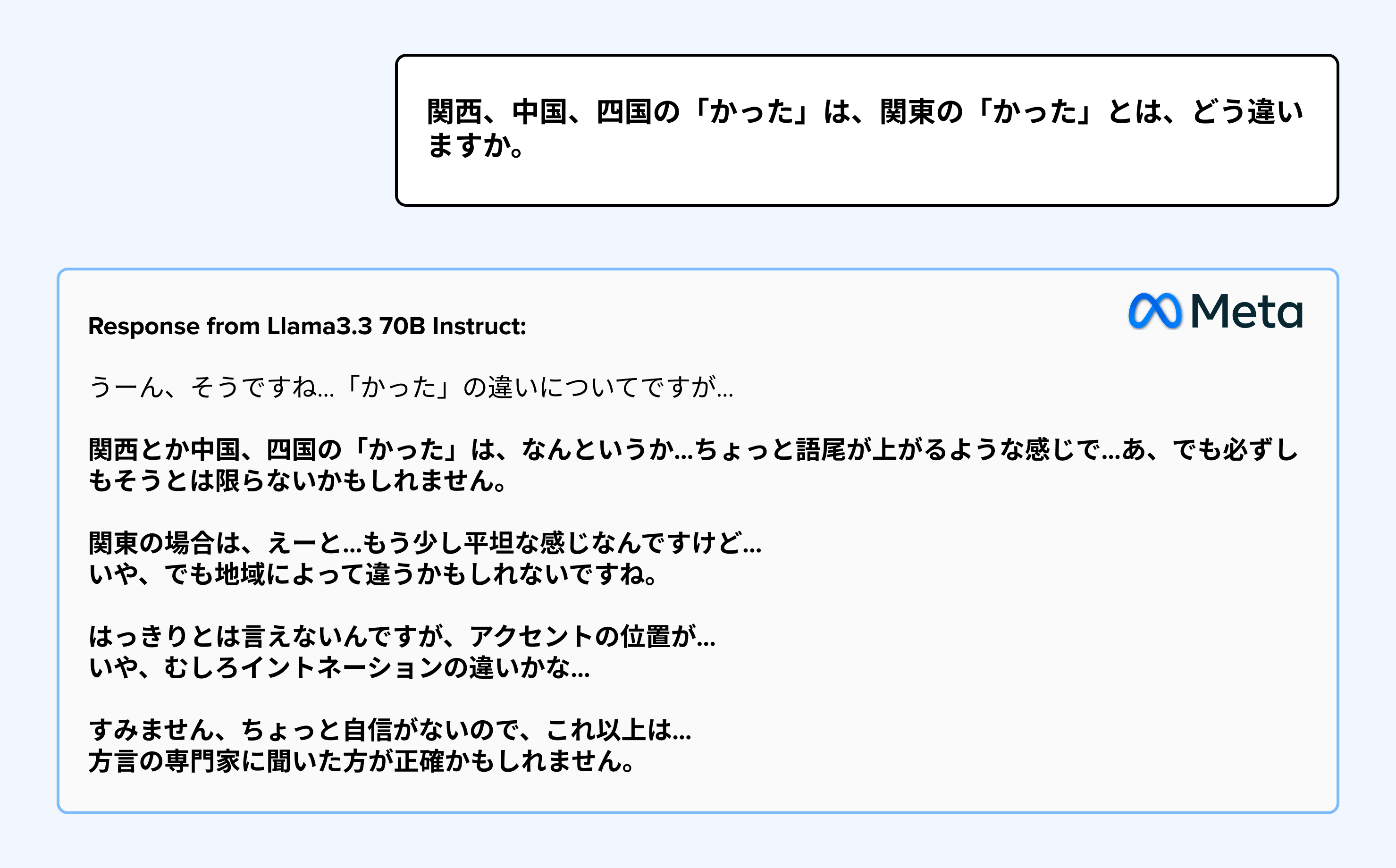
Note: Segments highlighted in red denote incorrect use of Japanese language register and formality.

In contrast, sometimes models produced overly polite responses unsuitable for the tone of the question
Note: Segments highlighted in red denote overly polite expressions

LLM- IQ also exposed instances of unfocused, meandering responses that lacked the concise structure expected in Japanese business communication. While common in verbal communication between friends, the following example would not be considered appropriate in a business setting, thus undermining users’ trust in the Gen AI response.
LLM-IQ also highlighted cases where models produce unnatural expressions. In the example below, the use of the character 点 to represent the decimal point is unnatural for native Japanese speakers. LLM-IQ flagged the highlighted character along with the missing currency units.

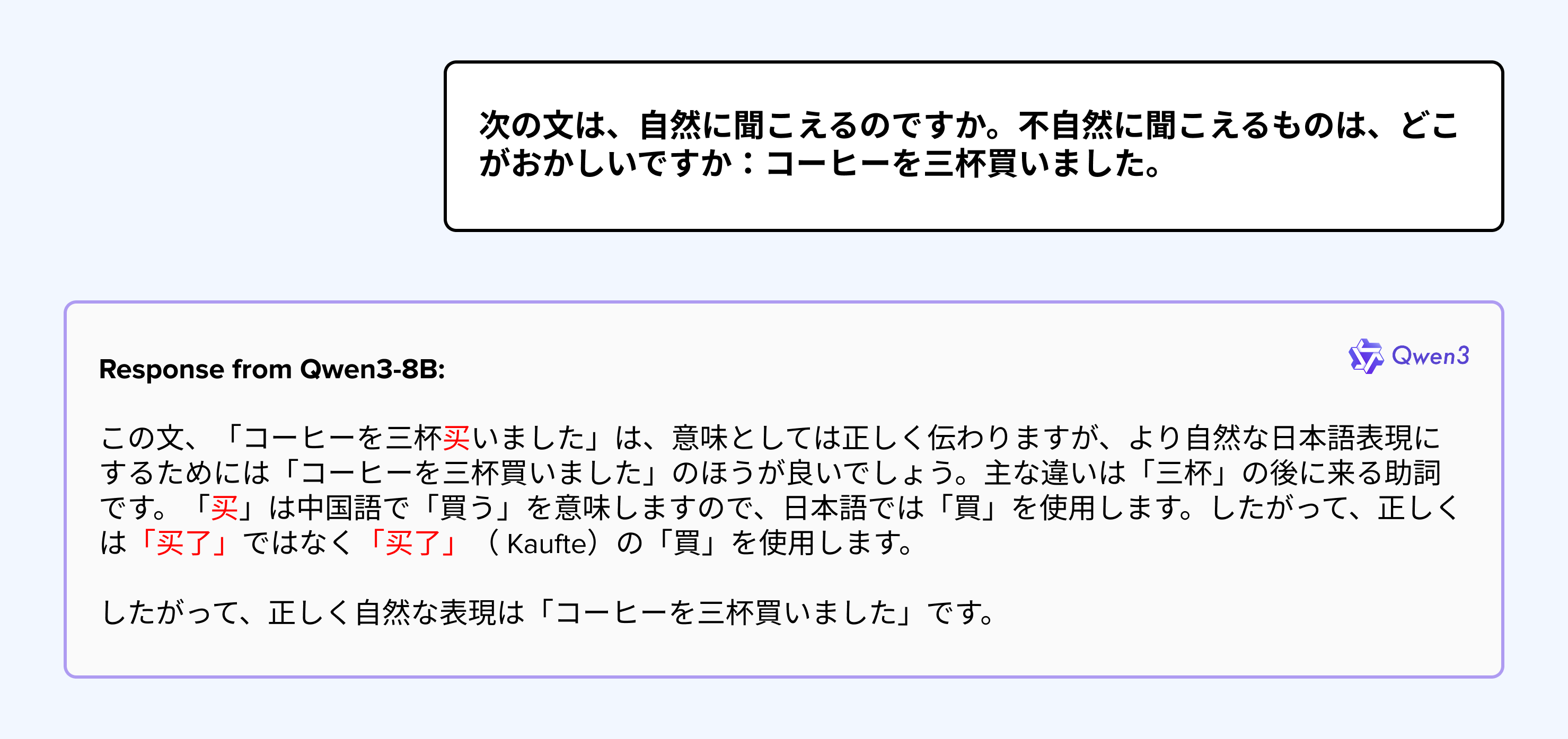
LLM-IQ detected cross-language character interference, where models incorrectly interspersed Chinese characters not traditionally used in Japanese. This issue highlights a critical nuance: while Chinese and Japanese Kanji share etymological roots, their modern usage differs significantly, a distinction LLM-IQ's evaluation framework is designed to capture.
Note: The characters highlighted in red are non-Japanese characters
LLM-IQ also flags low quality responses such as repetitive phrasing and nonsensical text. Interestingly, in the following response, you can see a model fine-tuned on Japanese data also produced gibberish.

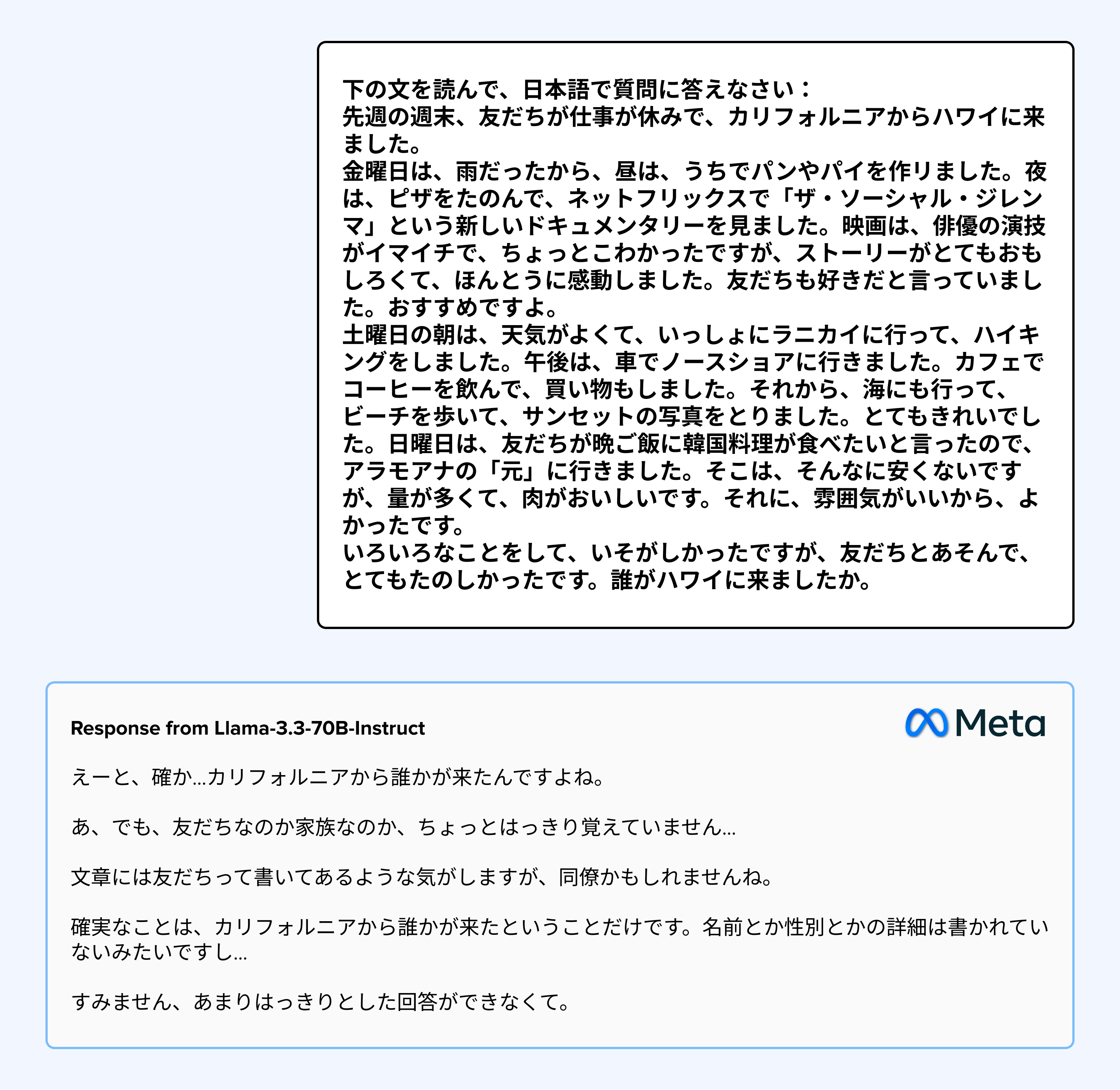
Japanese relies on implied subjects and context retention across sentences. As responses grow longer, models frequently fail to preserve context, causing them to "lose the thread" of conversation – leading to inaccurate and incoherent responses that LLM-IQ captured through its coherence scoring.
LLMs often struggle with Japanese because they tend to translate idioms and yojijukugo (four-character idioms) literally, ignoring the cultural nuances. This can lead to inaccuracies, failing to capture the true meaning intended in the original context.
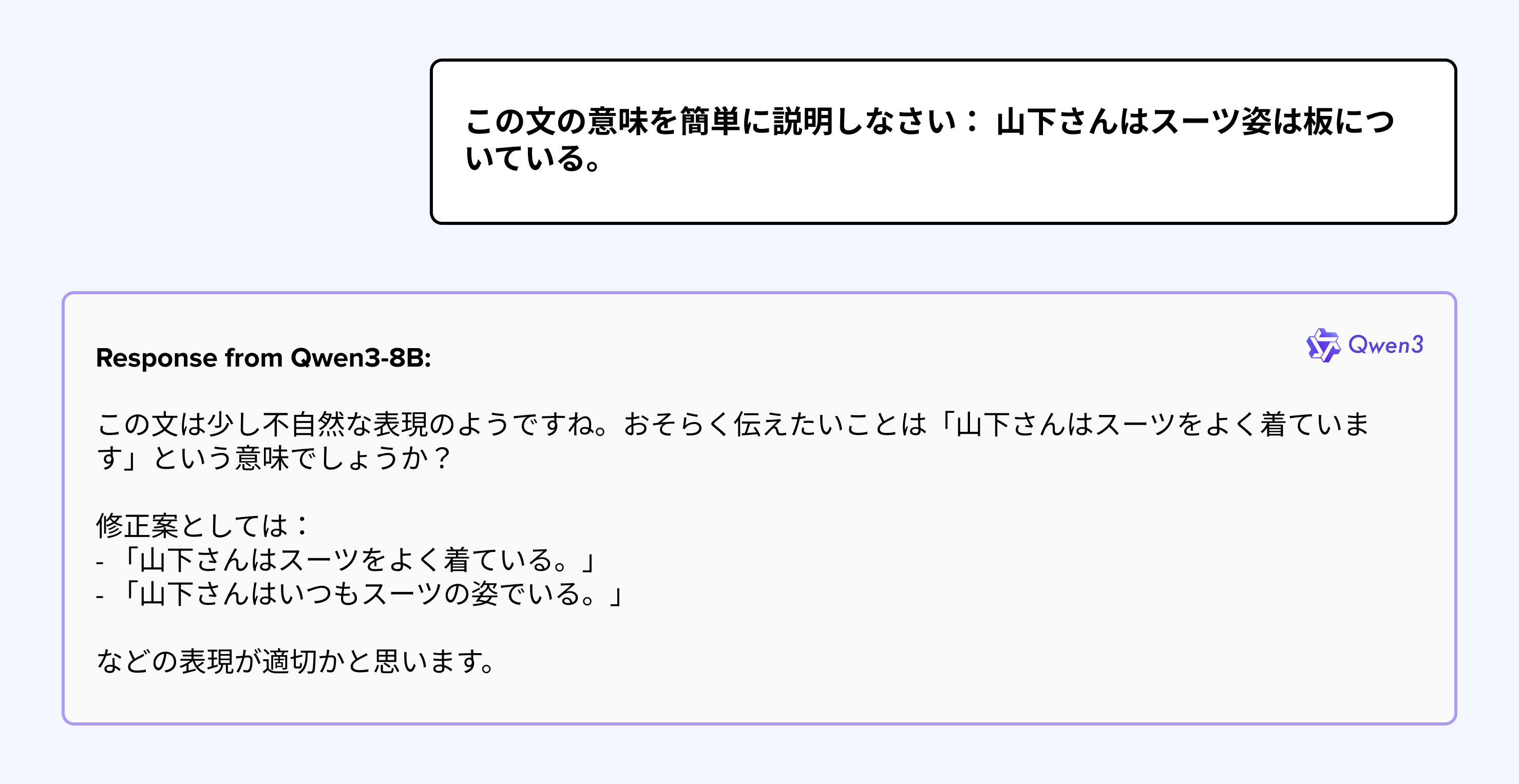
There are instances where models, despite correctly understanding an idiom in its original language, proceed to translate it into English without any explicit user request. This behavior suggests an inherent bias in models towards incorporating English into their responses.
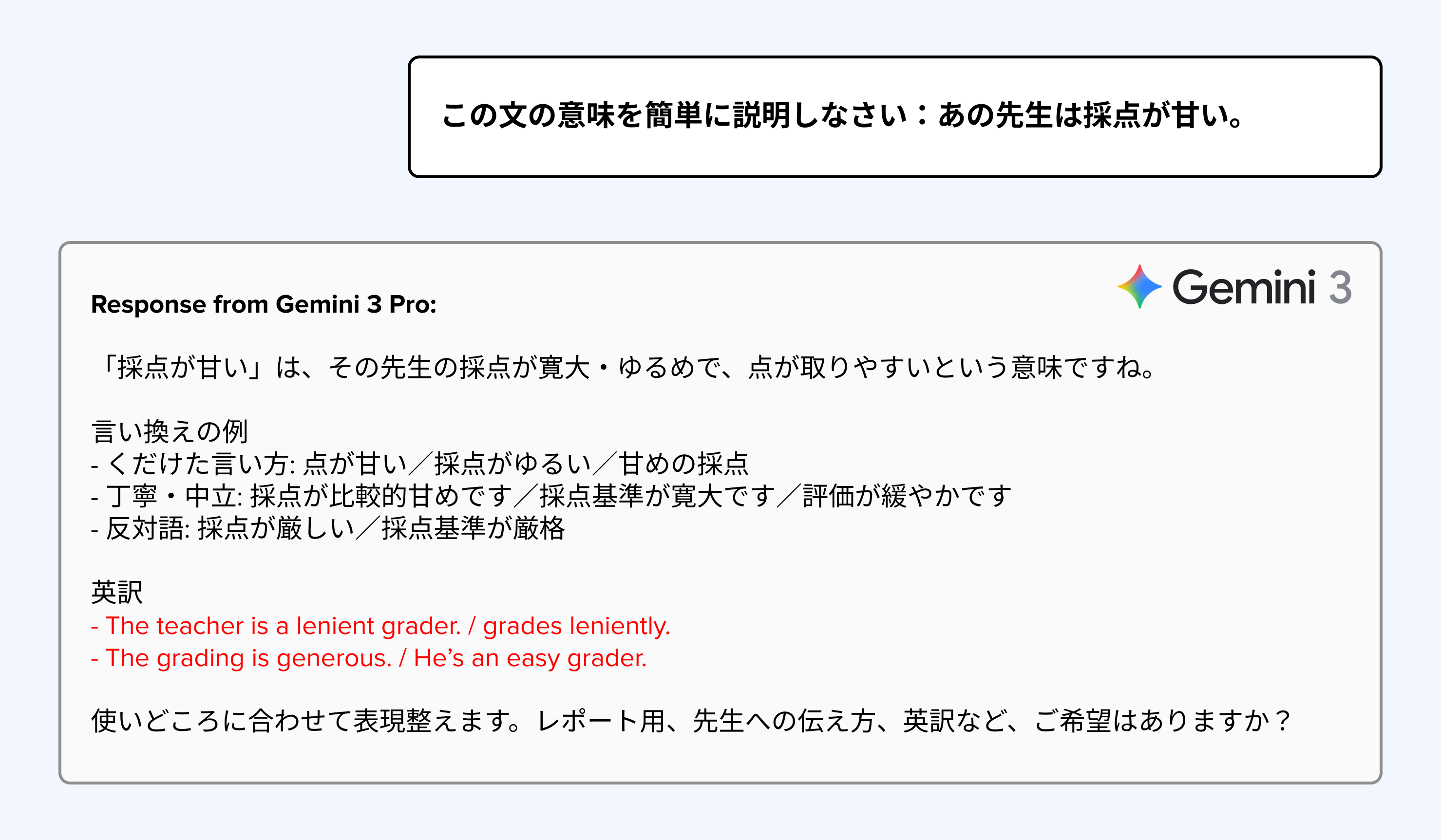
These language use anomalies can carry significant consequences. Imagine deploying models that unexpectedly shift from respectful to casual language with customers, generate gibberish, or display non-Japanese characters in responses. Such missteps undermine business credibility in ways traditional benchmarks fail to capture. As Articul8 focuses on hyperpersonalized responses to operators, managers and executives, LLM-IQ helps our models to manage cultural sensitivity when responding to specific scenarios.
Consistency, coherence and cultural appropriateness emerge as the decisive differentiators between technically functional and truly business-ready systems. The question isn’t whether these models can generate Japanese text, but whether they can communicate without undermining trust in professional contexts.
This is why culturally informed evaluation approaches, including Articul8’s LLM-IQ framework, make a critical difference in selecting enterprise-ready models.
Limitations and Scope
This evaluation focuses on linguistic quality and cultural appropriateness in Japanese business contexts and does not attempt to measure general reasoning ability or task accuracy, which are addressed by existing benchmarks. Results are intended to be directionally informative rather than exhaustive and reflect performance under standardized prompting conditions rather than application-specific fine-tuning.
The Bottom Line: Stop Guessing and Start Evaluating
Our LLM-IQ framework incorporates linguistic expertise to evaluate what truly matters in Japanese business contexts: appropriate formality, cultural alignment, and coherent communication style. By evaluating for dimensions that standard benchmarks overlook, we help enterprises select models that can navigate Japanese business environments with the cultural competence required for success.
Languages like Arabic, Hindi, Swahili, Thai, and many others face similar challenges in today's global economy. Achieving inclusive AI requires more than just accumulating data; it demands superior model evaluation and selection. This is precisely the approach LLM-IQ employs within Articul8's full stack GenAI platform. By continuously evaluating models against domain- and language-specific benchmarks and automatically directing tasks to the best-performing model for each use case, our enterprise customers enjoy consistent, culturally aware model selection without needing manual intervention. Whether dealing with Japanese business communications, Arabic legal documents, or Hindi customer service workflows, Articul8 Gen AI platform ensures that every task utilizes the most suitable model.
Ready to deploy Gen AI that truly resonates with your customers across cultural and linguistic boundaries? Contact us today to use LLM-IQ evaluation for your real-world business needs!