
Articul8 Research Accepted at NeurIPS Workshop Proving 40% Better Document Image Retrieval Than SOTA Models
We’re excited to share that our paper, DocQIR-Emb: Document Image Retrieval with Multi-lingual Question Query, has been accepted at the NeurIPS UniReps Workshop. This workshop is dedicated to advancing the science of representation learning, and it provides the ideal setting to present our work on improving how enterprises access knowledge from documents.
The Real-World Challenge That Motivated This Research
Enterprises generate enormous amounts of documentation filled with images, charts, graphs, and tables. Often, critical information is not in the text but in the visuals and tables. If someone asks, “What’s the trend in broadband internet access in Italy from 2005 to 2018?” the best way to answer is not with a block of text but by surfacing the chart that shows the exact trend.
This capability, known as Question-Image Retrieval (QIR), is central to making enterprise knowledge more accessible. However, it has remained a challenging piece of the document understanding puzzle.
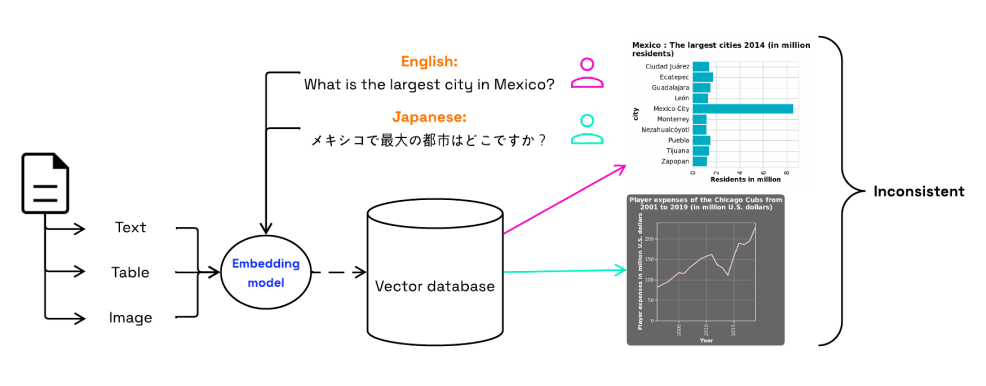
Figure 1: Illustration of Question-Image Retrieval (QIR) task. A QIR system aims to retrieve relevant scientific images or table images that accurately answer a user’s question, while also being robust to queries in multiple languages, enabling effective information retrieval across linguistic boundaries.
Why This Problem Matters Today
Most multimodal retrieval models in use today are designed for natural images, trained on massive datasets where the text can be as simple as a short caption describing the picture. That setup is worlds away from what enterprises need. Tables and scientific charts don’t look like photos, and business users ask in depth highly analytically forward questions.
Additionally, enterprises are global. A team in Brazil may ask questions in Portuguese, while a colleague in Japan may ask in Japanese. A trustworthy system that produces accurate results must work seamlessly across languages. Most of the existing models break down in this environment because they struggle with structured images, fail when queries are full questions rather than captions, and rarely support multi-lingual use cases.
How People Approached This Before
Prior attempts to tackle this problem largely extended text-to-image models like CLIP (OpenAI’s Contrastive Language-Image Pre-training model) into the document space. But because these models are tuned for captions, they misfire when faced with actual questions. They also lack the robustness to parse structured visuals like tables, which often require reasoning about rows, columns, and numeric relationships. And they were usually limited to English. The result was retrieval systems that simply weren’t accurate or flexible enough for enterprise use, where critical business decisions need full context.
What We Did Differently
To solve this, we made two key breakthroughs. First, we created the DocQIR, a large dataset of very high quality question-image pairs. Unlike existing datasets, DocQIR focuses exclusively on scientific figures and tables, and the test set includes five languages: English, Hindi, Japanese, Korean, and Portuguese.

Figure 2: Example question in 5 different languages associated with (top) scientific image and (bottom) table image
Second, we introduced DocQIR-Emb, a new architecture designed for multilingual, question-driven retrieval. It combines a multi-lingual text embedder, which ensures the same question asked in different languages maps to the same space, with a visual language model trained to understand scientific images and tables. Together, these components map both questions and images into a shared space, enabling accurate retrieval regardless of language or image type.
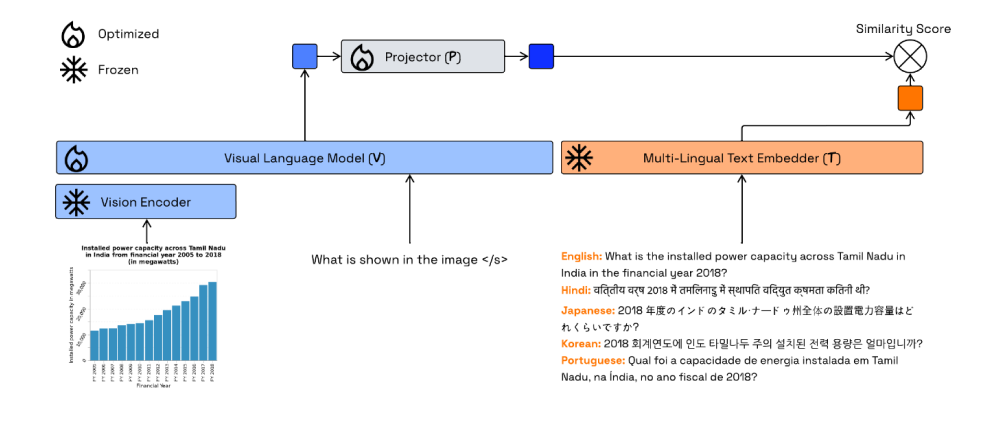
Figure 3: Architecture of the proposed DocQIR-Emb.
Snapshot Results
The impact was significant. DocQIR-Emb outperformed leading multimodal embedding models by more than 40% on multilingual question-image retrieval tasks. These gains held true across both scientific charts and complex tables, demonstrating the model’s robustness. While other models often returned irrelevant results, DocQIR-Emb consistently surfaced the correct image to answer the question. Just as importantly, the model proved effective across languages, showing that enterprises can now unlock document knowledge on a global scale.
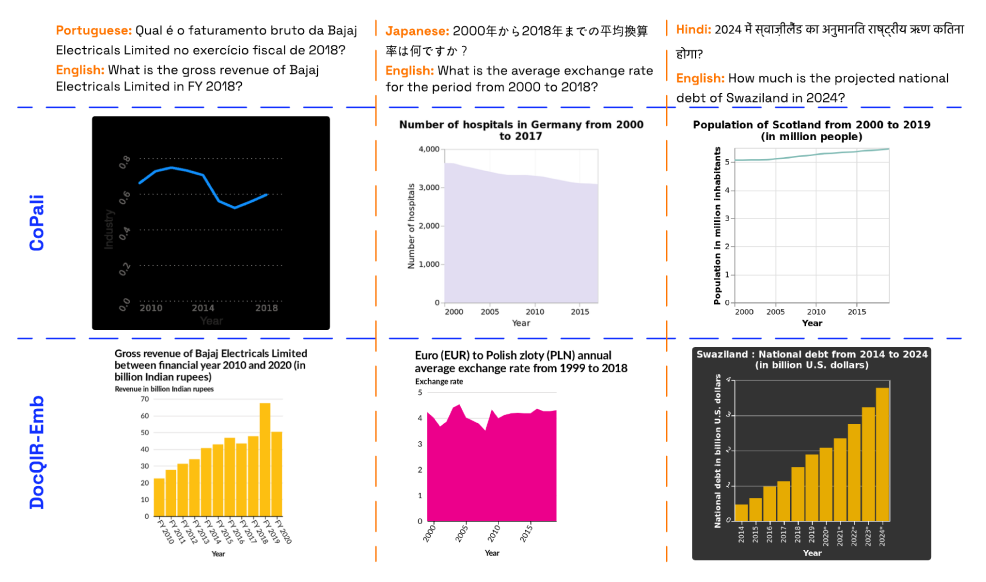
Figure 4: We demonstrate the effectiveness of our proposed DocQIR-Emb in retrieving relevant images for questions in multiple languages. The top row displays questions in Portuguese (left), Japanese (middle), and Hindi (right), along with their English translations. The middle row shows the most relevant images retrieved by the CoPali model, which fails to retrieve the correct images. In contrast, the bottom row shows the images retrieved by our DocQIR-Emb model, which successfully retrieves the correct images associated with each question, highlighting its superior performance.
Why It Matters for Enterprises
For businesses, this research goes far beyond academic results. As part of our proprietary data perception module, it enables faster access to insights across global teams, more intuitive ways of unlocking information hidden inside documents, and stronger support for decision-making across multiple languages. At Articul8, we believe that unlocking the value in your data requires moving beyond text alone and understanding the true “shape” of your data. With DocQIR-EMB, we’ve taken a significant step toward making enterprise AI smarter, more inclusive, and more globally relevant.
You can read the full paper here: DocQIR-Emb: Document Image Retrieval with Multi-lingual Question Query